
Microsoft Azure Arc-enabled Data Services: Tech Dive, Features, Planning
Managing multiple data centers and multiple clouds is possible with Microsoft Azure Arc technologies. That’s because you can extend data services enabled by Azure Arc anywhere to innovate everywhere for your business.
What are Azure Arc-enabled data services?
Azure Arc is a set of services and tools that allow you to build applications and services, while giving you the flexibility to run workloads across data centers, at the edge, and in multi-cloud environments.
Azure Arc-enabled data services are available as an offering of Microsoft Azure Arc. These data services enable your DevOps teams to run SQL Managed Instances or PostgreSQL without operational overhead. Key service features, such as always current, elastic scale, self-service provisioning, unified management, and disconnected scenario support, are creating a cloud-like experience on any infrastructure.
Azure Arc-enabled data services client cases
Most commonly, organizations that keep their resources on-premises due to legal regulations (for example, those organizations in the FinTech or healthcare industries) benefit from Azure Arc-enabled data services. It also rescues those businesses having edge locations, with prolonged periods of outages (for example, remote mines and mineral deposits, factories, or even cruise ships).
You can learn how this technology can transform the management of your resources by checking out the way Microsoft boosted John Deere’s business with Azure Arc-enabled data services. The solution enhanced John Deere’s on-premises environment to the cloud level, which significantly reduced the load on its infrastructure team and unlocked scaling potential.
SoftServe recommends considering Azure Arc-enabled data services if you deal with the following kinds of deployments at your organization:
- On-premises
- Hybrid
- Multi-cloud
How do Azure Arc-enabled data services work?
The illustration below explains the Microsoft Azure Arc-enabled data services architecture.
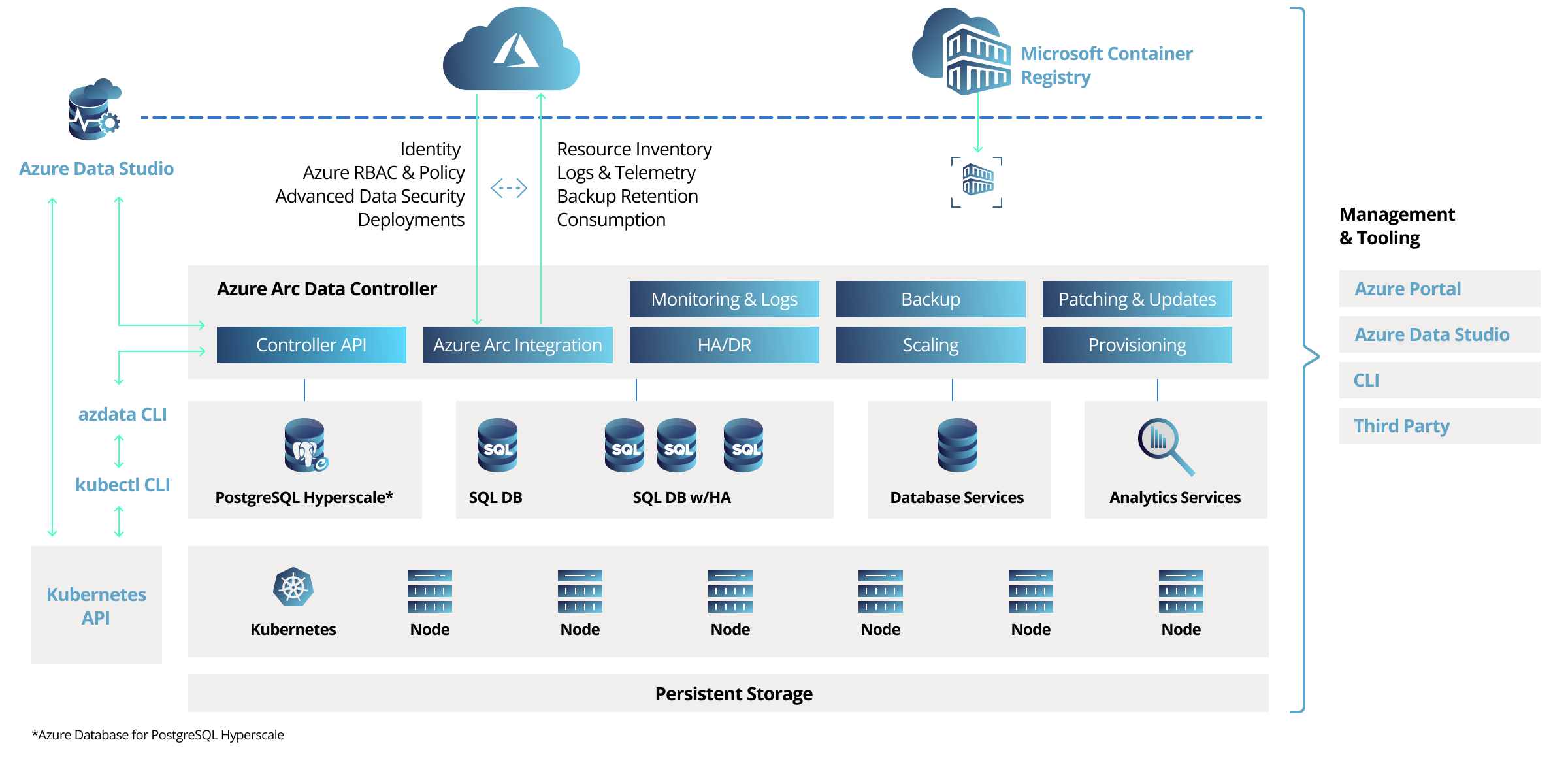
Azure Arc data services are implemented as a Kubernetes controller (the data controller). This allows your DevOps teams to deploy data services (Arc SQL Managed Instance or PostgreSQL Hyperscale) on top of the Kubernetes cluster. It supplies them with a choice for connecting to Azure using two different connectivity modes: directly connected and indirectly connected.
The connectivity mode gives your DevOps teams flexibility to choose how much data is sent to Azure and how they interact with the Arc data controller. Depending on which connectivity mode is chosen, some functionality of Azure Arc-enabled data services may or may not be available, and some implementation details may differ.
- Indirect connectivity mode allows your DevOps teams to work offline and requires fewer components to install on the Kubernetes cluster. It lacks some of the features of direct connectivity mode. It also requires them to implement scheduled uploads of usage data to Azure.
- Direct connectivity mode gives your DevOps teams more features, such as automatic uploads of usage data, management from Azure Portal, and automatic updates, while requiring an internet connection and Arc-enabled Kubernetes cluster.
Azure Arc-enabled data services features
The key features of Azure Arc-enabled data services are creating a cloud-like experience on any infrastructure. But each feature has its own challenges, which you must be aware of as you plan deployment.
Always current allows you to get frequent updates with new features and patches, just like with Microsoft Azure. With this feature, you will never face “end of support” for your installations, because Azure continuously delivers updates.
In direct mode, you plan and control the system update, because the data controller update is a manual procedure.
The upgrade experience is the same using indirect mode. But you also must plan a way to deliver artifacts to the cluster. There are two options to carry out this:
- Pull new versions of Docker images for the data controller and data services, then transfer them to the Docker registry, which is available for the cluster, where the data controller is installed.
- Connect the cluster, where a data controller is installed, to the internet.
Elastic scale allows you to dynamically scale databases up or down, just as it’s done in Azure. However, you must know that scaling is still limited by the underlying infrastructure. (As of the writing of this article, it’s a manual procedure for both SQL Managed Instance and PostgreSQL Hyperscale.)
SQL Managed Instance comes with two tiers: General Purpose and Business Critical. General Purpose has only one instance, which can only be scaled vertically. Business Critical comes with a read-write and read-only replica, and it can only be scaled vertically. You can’t change the tier without re-provisioning. So, you need to carefully plan to choose the tier for your SQL deployment.
Right now, PostgreSQL Hyperscale has only one tier, and the scaling is easier than with SQL Managed Instance. You can scale the nodes up and down, but underlying Kubernetes pods may be rescheduled. You can also scale in and out horizontally through the Citus extension, which comes with the deployment. (As of the writing of this article, Arc-enabled PostgreSQL is still in preview. So, check the latest documentation before planning a POC.)
Self-service provisioning and unified management allow you to deploy a database in seconds, using either GUI (Azure Portal or a separate tool, called “Azure Data Studio”) or CLI tools.
In direct mode, management of resources can be done through Azure resource manager (Azure Portal, az CLI, ARM templates, API calls) and data controller (Azure Data Studio, kubectl). Metrics are available in both Azure Monitor and locally (Grafana and Kibana).
In indirect mode, management of resources can only be done with the data controller (Azure Data Studio, kubectl, and az CLI with “--use-k8s flag”). Metrics are available locally (Grafana and Kibana) and after upload to Azure in Azure Portal.
The automated backup and restore features are self-explanatory. Backups are periodically performed and only stored in the local cluster for both SQL Managed Instance and PostgreSQL. There’s no built-in way to enable the upload of backups to the cloud. The backup frequency is also static and can't be changed.
SQL Managed Instance does have other limitations you must be aware of when planning a deployment.
Capacity planning and pricing for Azure Arc-enabled data services
Fortunately, Microsoft Azure Arc-enabled data services come with well-documented sizing guidance. But there are a few key points you must keep in mind as you plan deployment.
- The baseline size for a given Azure Arc-enabled data services environment is the size of the data controller, which requires 4 cores and 16 GB of RAM.
- You must make sure that there are enough allocable resources for the planned workload, including storage.
- Currently, pricing is only available for Arc SQL Managed Instance, and it’s based on the number of cores.
- When using a directly connected mode, there can be added charges for the Arc-connected Kubernetes cluster. (Pricing is based on the number of vCPUs.)
Conclusion
A hybrid deployment can be a challenge for modern organizations. But working with a trusted cloud partner experienced with Azure Arc-enabled services allows you to put in place a unified management system of all virtual assets and have them well organized and transparent.
With Microsoft Azure Arc-enabled data services, you can simplify the management of multi-cloud and hybrid infrastructures and boost your on-premises to the cloud level.
Let’s talk about how SoftServe and its cloud experts can help you innovate your business from everywhere with Microsoft Azure Arc-enabled data services.