
The amount of data generated and analyzed throughout life sciences and omics-related domains has skyrocketed. Today, patient information is collected in real-time and further used to extract treatment or observational insights, for example, during decentralized clinical trials. Artificial intelligence (AI) advancements now enable a more efficient data-driven approach to drug discovery, development, and repurposing. AI also allows for more accurate personalized medicine by analysis of molecule data and patient data collected during clinical trials.
At SoftServe R&D, we focus our efforts on the life sciences domain to empower pharmaceutical companies and research organizations to build more efficient drug discovery and clinical trial workflows.
Our story
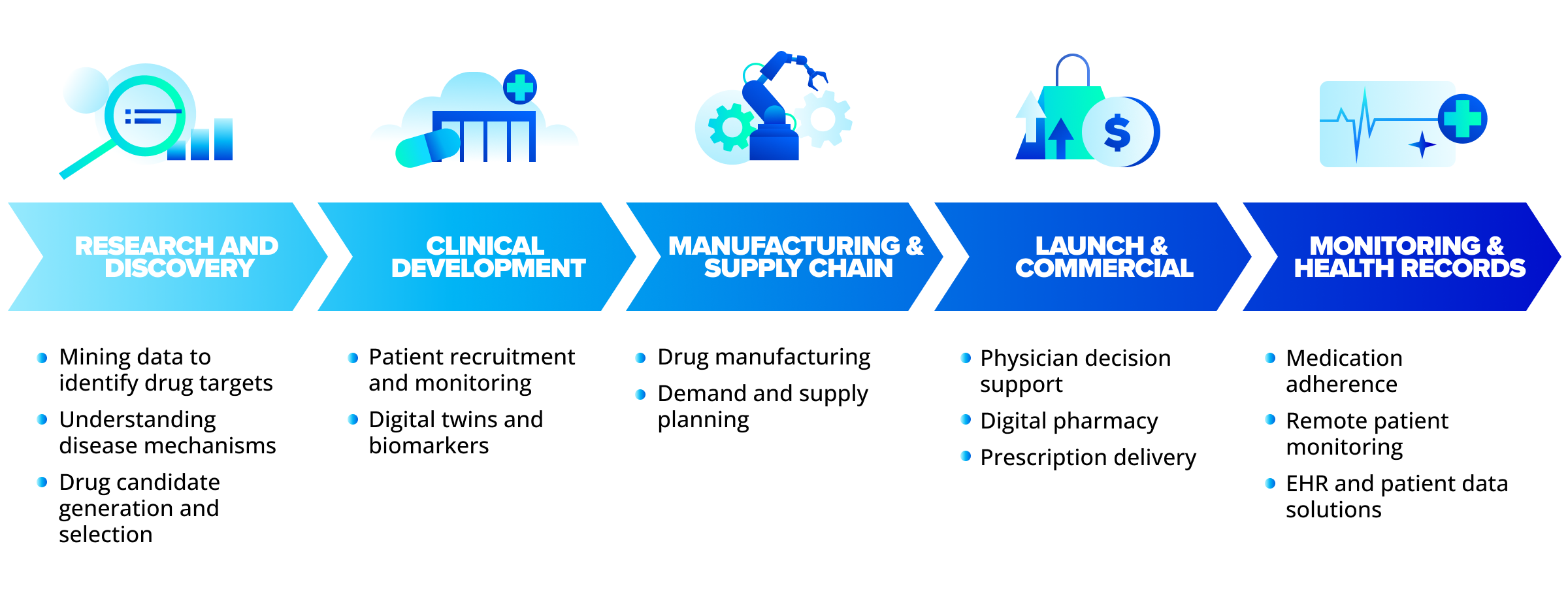
Life sciences technology trends
The life sciences market landscape is constantly developing as modern technologies are introduced. With those technologies come new tactics and approaches. It is essential to keep abreast of the latest novelties. We explore future trends of three life sciences submarkets: life sciences analytics, drug discovery, and personalized medicine markets.
- As reported by Expert Market Research (EMR), the global life science analytics market gained $23B in 2020. By 2026, the market is expected to be valued at $47B, growing at a compound annual growth rate (CAGR) of 12.7% in the forecast period of 2022 to 2027. This segment is driven by an increasing prevalence of chronic diseases, technological advancements, and rising demand for improved data standardization. Moreover, the growing adoption of analytics for sales and marketing apps will further enhance market growth.
- According to Verified Marketing Research (VMR), the drug discovery market size was valued at $39.02B in 2020 and is projected to reach $73.17B by 2028, growing at a CAGR of 8.2% from 2021 to 2028. Today, major pharmaceutical companies performing drug discovery and informatics processes have shifted their focus to gaining a foothold in emerging economies to expand their business operations and explore new markets.
- Based on Grand View Research, the global personalized medicine market size is expected to reach $796.8B by 2028. The market is expected to expand at a CAGR of 6.2% from 2021 to 2028. The market growth can be attributed to the high adoption of advanced genome sequencing instruments, the launch of companion diagnostics, and the rising incidence of cancer and other genetic disorders.
To address these challenges, pharma companies are seeking partnerships for the development of new therapeutic molecules, improving data standardizations, and launching new ways of diagnostics and drug discovery, which are driving the market.
At SoftServe we are partnering with and helping Contract Research Organizations (CRO) and pharma companies use AI and machine learning (ML) to speed up development, while at the same time constantly analyzing and researching market benefits and profits.
Because data is collected in real-time with a greater need for data-driven approaches, leaders of pharma companies need a way to quickly crunch the numbers. SoftServe’s team focuses on the development and application of AI/ML methods to problems emerging in natural sciences, including pure classical and hybrid classical-quantum computing solutions. We predict properties of compounds and materials based on their structure and composition or, vice versa, suggest chemical compounds with desired properties.
Because the chemical space of potentially synthesizable compounds is huge, plain traversing over all potential atomic combinations and arrangements is infeasible. Our mission is to develop methods to help navigate this space effectively by teaching computers to optimize the search.
Focus areas
Elevating the patient experience
SoftServe empowers companies across the bio- and chem-informatics domain, focused specifically on early drug discovery. As AI/ML methods are data demanding, we either search for available data or use customer data to train corresponding ML models. SoftServe also offers solutions for drug dosage optimization, hospitalization risk prediction, or other patient-centered tasks. Our team empowers our clients to build data platforms to host third-party solutions or in-house developed ML models, store data, and generate reports.
The SoftServe team is unique
Our team consists of people with backgrounds in computer science, physics, biology, and chemistry, having experience in academia and industry. A multidisciplinary composition allows us to attack problems from different angles and test different approaches to choose the best solutions.
Working in industrial R&D is much like running academic research—we shape the problem, read the papers to understand past methodologies and results, ideate potential approaches, then implement and test them. Therefore, it is important to have people from academia in the team—they know how to conduct the research.
During project implementation, we also consider business value—hence the industrial experience is important. Our team collaborates with other SoftServe teams as well as academic research teams across the globe.
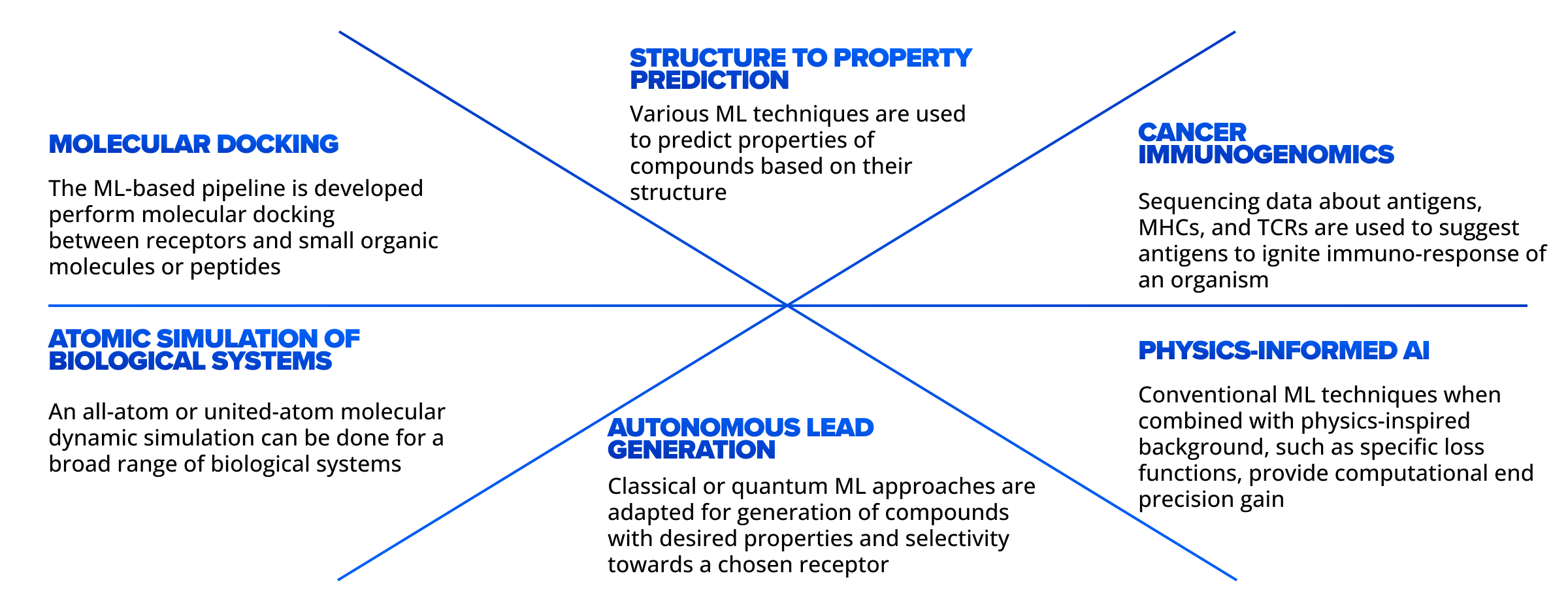
Spotlight on early drug discovery
Since 2018, we’ve focused mostly on early drug discovery, with ongoing projects built on top of earlier ones. This allows us to constantly improve and widen our expertise.
Our first project was dedicated to the development of an AI/ML-powered pipeline to generate small organic molecules and predict their properties, like solubility, toxicity, and mutagenicity. Moreover, the modular structure of the proposed pipeline allowed for adding new property predictors. The goal of the generative part was to look for compounds residing “in vicinity” of known drugs. As it was our first study in the field, we had a steep learning curve before gaining a critical mass knowledge to align with both the industry and scientific society.
Reduce errors with binding affinity. Understanding the market requests, we extended the pool of predictors with a drug-target binding affinity, which measures the interaction strength between a protein (target) and a drug molecule (ligand). The stronger the attraction between target and ligand, the stronger the therapeutic effect achieved by a lower drug concentration. One study within this track involved an ensembled pipeline including voting ensembles of different ML techniques over different chemical representations. This multimodal setup was more effective than a single-manner approach. An ensembled approach compensates for errors of one ML technique by other techniques, weaknesses of one representation by strengths of other representations.
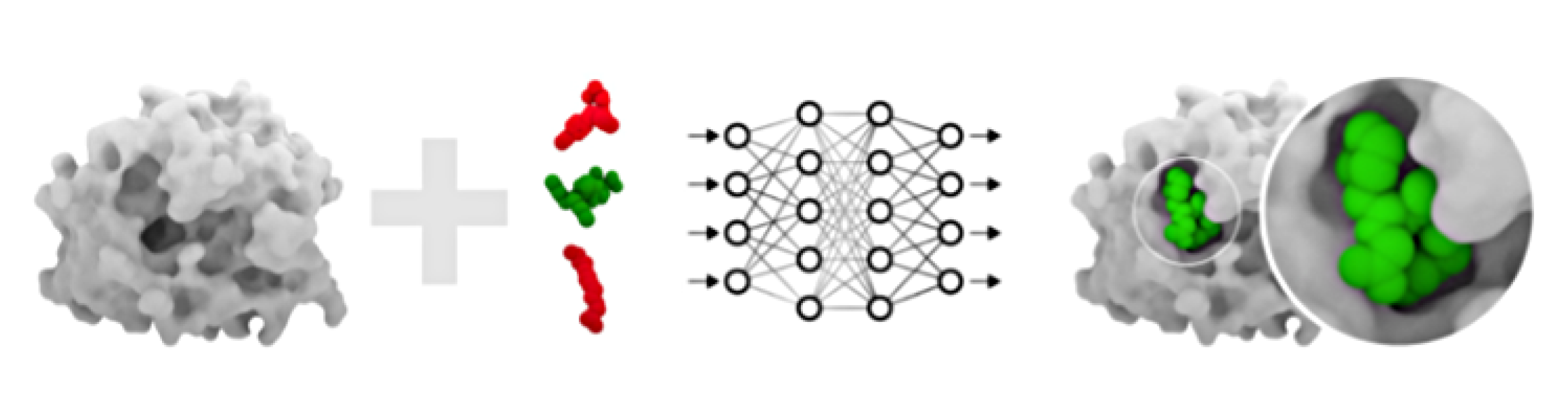
Increase accuracy with molecular docking. Binding affinity reflects the strength of attraction between a receptor and a candidate molecule but says nothing about the binding region. Knowledge about binding regions is important in drug design as it clarifies how a molecule interacts with a receptor. Within this track, we developed an AI/ML-powered pipeline for molecular docking. The solution involves an in-house developed deep neural network to localize a binding region on the protein surface. AutoDock Vina is used in the second stage to adjust the pose of the ligand within the binding region. The localization stage demonstrates state-of-the-art accuracy, while being much faster than traditional solutions.
Increase speed with autonomous drug design. Using our experience in the generation of chemical structures and prediction of their properties, we applied ML techniques to tackle autonomous drug design. Within these lines, we worked on the development of reinforcement learning agents and hybrid classical-quantum computing ML approaches to navigate the above-mentioned chemical space effectively, rather than exploring it by a grid search. In such a setup, a set of property predictors provide rewards for a generator, giving them hints of whether new generations of drafted molecules improve the properties.
Improve efficiency with atomic computer simulations. We also offer our expertise in atomic computer simulations, a powerful tool for the validation of mechanisms of intermolecular interactions. The simulations of macromolecular systems are often long and computationally intense, thus, the AI/ML-based screening stage preceding heavy simulations serves as a sieve to filter out weak drug candidates and pass more confident ones to a deeper analysis (computer or wet-lab experiment).
Increase accuracy with yield prediction. Chemical synthesis planning is a challenge in the chemical industry. Most chemicals require a chain of synthesis reactions, hence, the route over reaction types and reactants along the synthesis process is often a subject of optimization. Within this track, we collaborated with an industry partner who shared their commercial dataset of chemical reactions along with the reaction yields—mass percentages of reactants versus reaction products. We developed a deep neural network predicting the yields based on the structure of reactants. Further, such a yield predictor can be used in retrosynthesis to plan the most efficient synthesis routes.
Technology and research frameworks
As AI/ML is the core component in our research, the technological stack includes Python and a set of libraries for machine learning, data science, statistical analysis, and bioinformatics. Here are the steps followed:
- Before training ML models, we find appropriate data, check it for consistency, and decide which setup (supervised versus unsupervised, or what ML technique) is the most suitable for the case. This stage mostly involves reading papers about datasets and state-of-the-art solutions to date.
- Having a vision for the approach, we start from a simpler implementation and iteratively improve it. It is difficult to predict what type of neural network architecture or a hyperparameter set will work best.
- The obtained results are verified experimentally, either in a lab or by a computer experiment.
From the perspective of computer experimentation, our team members also have experience with a few packages for computer simulations.
AI/ML-guided selection of inhibitors
Future projects at SoftServe
Today, we are researching and developing across several new domains. Recently, we acquired a client project on drug dosage optimization. Having historical patient data along with drug dosages, we distinguished certain patient patterns (of different susceptibility to the drug) and suggested the most efficient treatment course. As we aim to expand our expertise, one of our ongoing research tracks is dedicated to the development of cancer immunotherapies.
Collaborating with our quantum computing R&D team, we also look for opportunities in the development of new hybrid approaches which brings together strengths from both worlds. Finally, our expertise in molecular design can be scaled to the search for novel materials.
Talents and partnerships
As our research tracks are often scientifically intense, we look for people with natural sciences backgrounds. Data science and AI/ML experts are also welcome. Even a lack of some of these components is not critical, we conduct knowledge-sharing sessions, discussions, and constantly work on the professional development of our experts.
We have partnerships with academia and industry and are always looking for new relationships. Having a partnership network helps us commit to multidomain tasks and gain new experience, while AI/ML methods are quite universal and can be easily adapted for different use cases.
Recap
- SoftServe’s R&D empowers companies to go beyond existing barriers to discover innovative and beneficial solutions—saving time, money, and creating new opportunities.
- R&D as a service (RDaaS) delivers long-term benefits from delivering new market differentiators to enhancing existing products and solutions.
If you’re searching for more efficient drug discovery, personalized medicine, and life sciences pipeline solutions, let’s talk about how SoftServe technology solutions can accelerate your R&D initiatives. Reach out and learn more about SoftServe’s life sciences R&D on our website.