
Customers are demanding more personalized experiences in every facet of their lives—across retail, healthcare, energy and financial services industries. The only way to meet this demand is by leveraging data to deliver hyper-personalized experiences. SoftServe helps our clients achieve seamless, immersive experiences their customers demand—driven by data, optimized by analytics, and evolving in cadence with consumer demands.
Case studies across various markets and industries address common personalization problems, such as personalized recommendations, finding related items and products, personalized search ranking and marketing promotions based on customer behavior.
Solving personalization problems often requires dealing the complexity of the real world, such as:
- Infinite variety of personalities and factors
- Complex non-linear relationships
- Dynamic changes in human behavior
- Natural uncertainty
Traditional rule-based approaches are limited in their capabilities and require incorporating deep subject domain expertise. Instead of manually defining the rules, machine learning introduces a bottom up approach by learning the optimal solution from historical data.
Since Netflix held their original Netflix Prize competition back in 2009, deep learning de facto became the state-of-the-art technique for solving personalization problems and plays the core role in complex recommendation systems at Amazon, Uber, Spotify, and others.
Despite the Deep Learning's potential to solve any problem supported by the data (see Universal approximation theorem), training an ML solution is an iterative process that involves a lot of experimentation and prototyping.
Modern deep learning models, such as Recurrent and Convolutional Neural Networks, require careful tuning and optimization. Navigating through their multidimensional hyperparameter and design space is almost impossible without prior background and expertise in ML. Still, the empirical side of ML is far ahead of the theoretical.
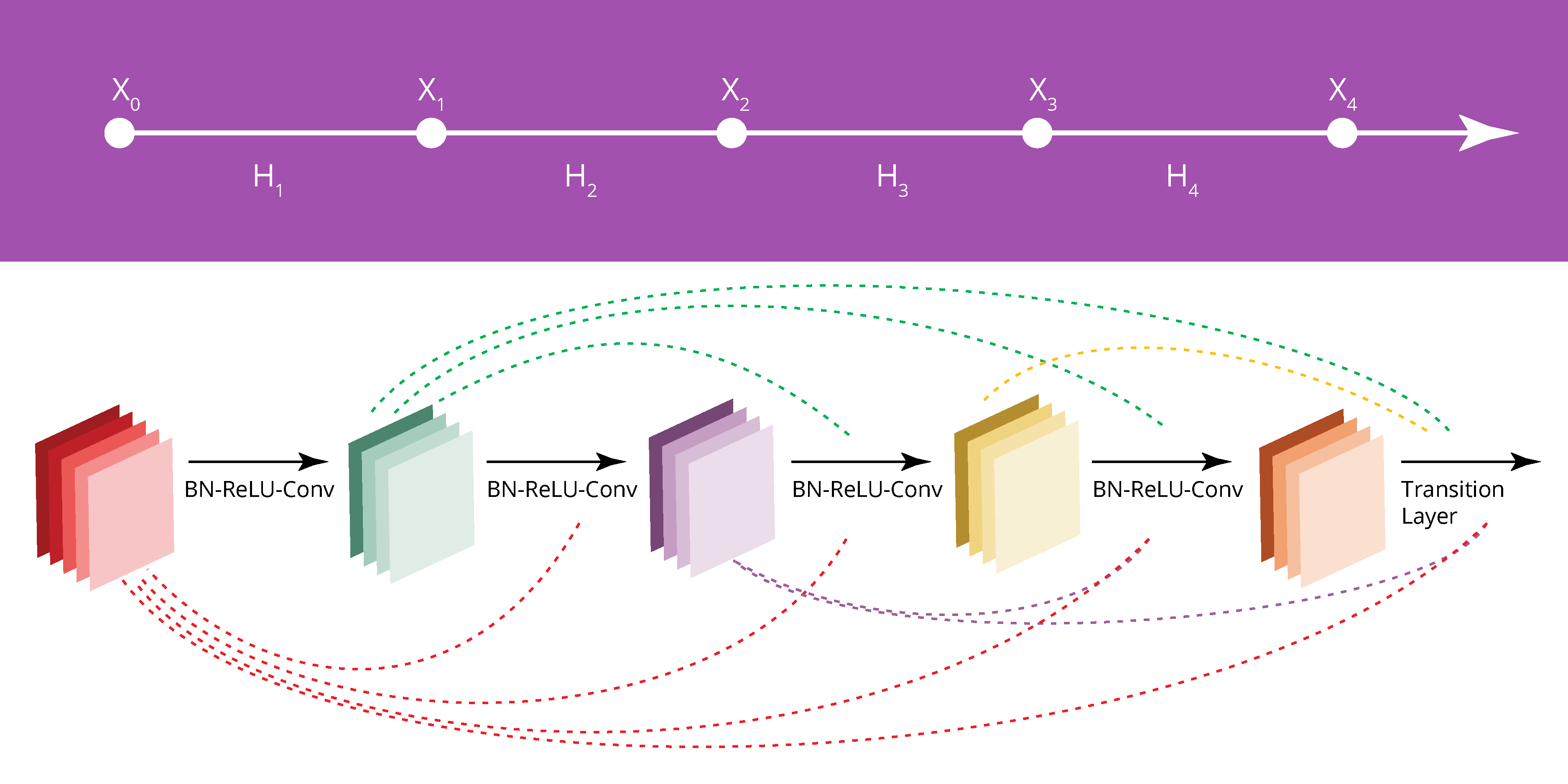
An example of a Densely Connected Convolutional Neural Network (DenseNet) architecture that has more than 800,000 trainable parameters.
Building up in-house ML competency could be a significant challenge for enterprises, as it involves establishing data-driven processes and hiring rare experts from the high-demand AI/ML market.
Moreover, starting from a small AI/ML experiment or a proof of concept, all the way down to the production-grade system, a machine learning solution lifecycle and infrastructure cover much broader space than just an ML model code. It often consists of multiple stages, workflows and many different building blocks and components.
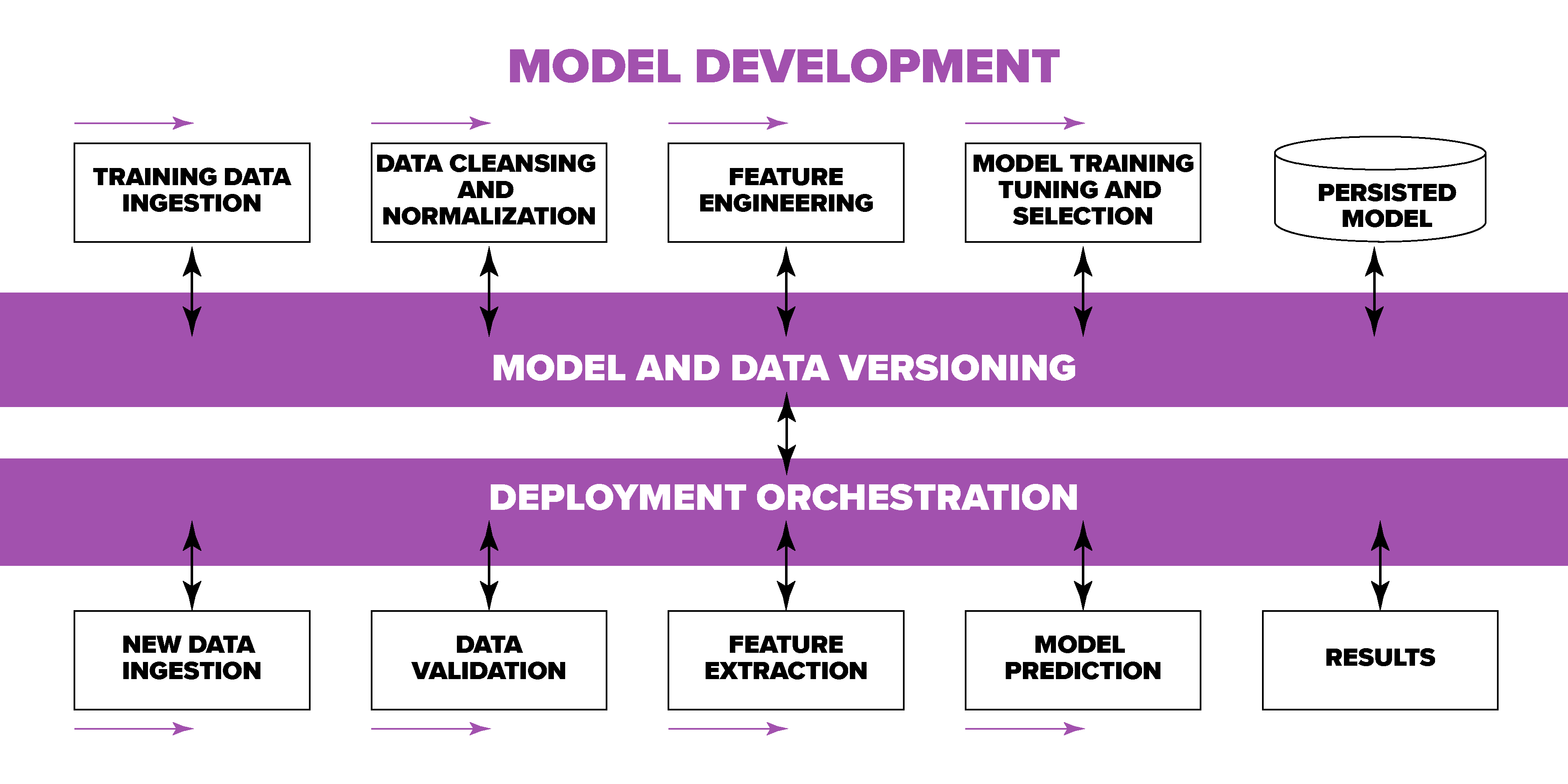
Maintaining ML models in production requires well-established processes and workflows. In the same time, machine learning introduces fundamentally new challenges for traditional SDLC and CI/CD lifecycles due to its “data-driven” nature that defines the behavior of the system:
- ML-specific operations that depend on the data (i.e. data versioning, feature extraction, model training, evaluation, tuning and serving)
- Complex landscape of various ML tools, libraries, frameworks, platforms and hardware accelerators
- Large scale ML workloads often involve multiple data sources of different kinds and ownership
- Success depends on cooperation of multiple teams and stakeholders with poorly separated responsibilities and different workflow speeds
- Production ML deployments require constant monitoring, quality control and ability to debug and interpret critical issues
All these challenges may impact solution's performance and bring significant IT & operational costs in case of sub-optimal design decisions and infrastructure limitations.
Amazon Personalize eliminates most of these challenges by providing a fully-managed ML infrastructure and AutoML capabilities that allow building custom ML recommendation systems with minimal efforts. It democratizes machine learning development by leveraging the power of the same technology used at Amazon.com and making it available for experts without extensive machine learning experience.
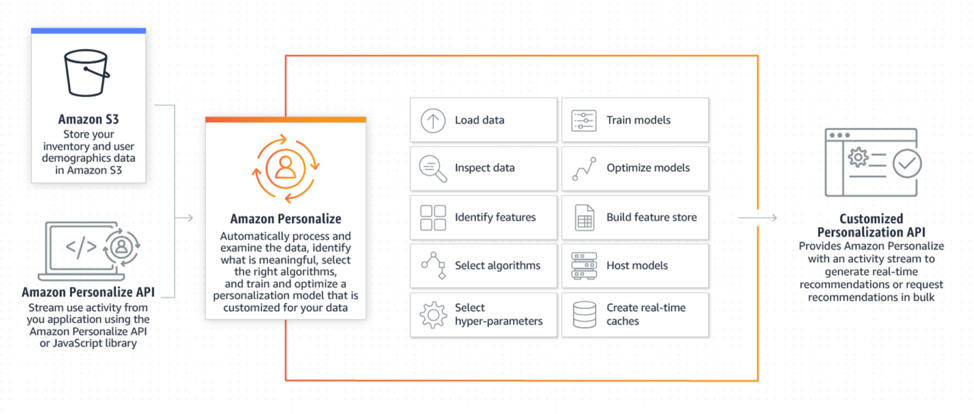
Amazon Personalize provides multiple interfaces for users with various prior background. A user can train, manage and deploy high-quality models using either web console, command line interface or Python programming SDK.
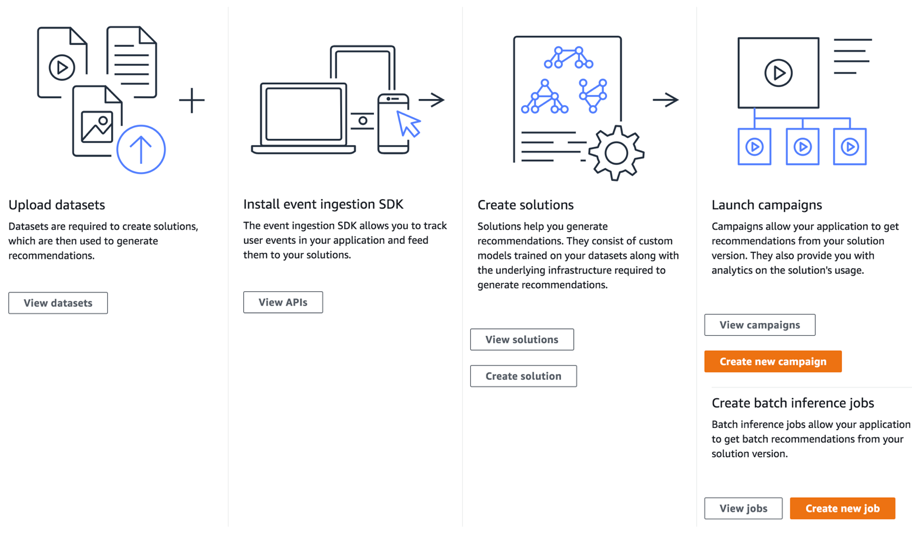
The Amazon Personalize workflow for training, deploying, and serving recommendations consists of the following steps:
- Upload and describe historical training data
- Select a model type to train or let Amazon Personalize find the optimal solution
- Schedule training and evaluation jobs
- Analyze training performance metrics
- Deploy the solution for serving
- Provide recommendations for users
Amazon Personalize is able to learn from data of various types and nature, including:
- Web logs and click streams
- Sales and purchase history
- Transactional data
Minimal data transformations efforts may be required to export data to CSV format.
Amazon Personalize comes with predefined recipes that automate training complex ML models (i.e. Hierarchical Recurrent Neural Networks) for common personalization use cases. A user can either customize a recipe or use AutoML to automatically learn the optimal parameters from multiple experiments (also known as hyperparameter tuning).
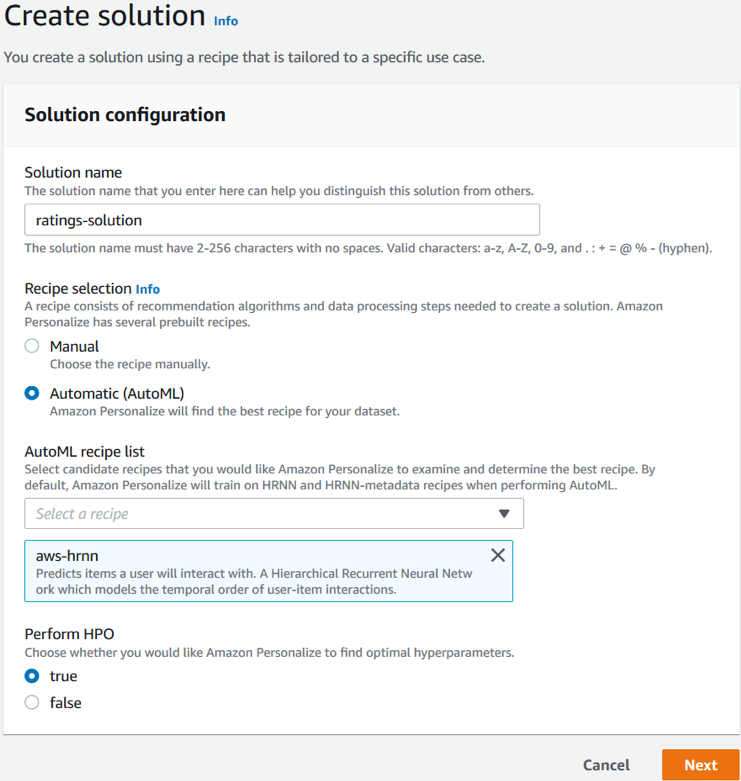
Training an ML model with Amazon Personalize is as simple as clicking a button. Amazon Personalize will take care of all the underlying infrastructure, resource management, job orchestration, data transformations and actual recommendation model training and testing. Amazon Personalize also takes care of model and data versioning which allows comparing different experiments using popular ML performance metrics.
If a trained model satisfies target performance metrics, it can be deployed for serving real-time and batch recommendations. Amazon Personalize provides mature APIs and integration capabilities for the most common programming environments (JS, PHP, Python, Java, .NET, Go, C++ and others).
Amazon Personalize can also capture live events and user interactions to provide recommendations based on both real-time user sessions and historical data. This allows the solution to continuously learn from new data and improve recommendations over time. Amazon Personalize groups user experiences by sessions for more contextual recommendations.
Those who can leverage from Amazon Personalize the most are engineering teams, citizen data scientists and subject matter expert interested in delivering personalized user experiences. Amazon Personalize provides high-level abstractions (i.e. solutions, campaigns, events) that don’t require prior ML expertise.
Experienced data scientists can still use Amazon Personalize for rapid prototyping and experimentation to validate their ideas and release initial recommendation solutions or MVPs.
Amazon Personalize can be also be deployed alongside custom machine learning models deployed on Amazon SageMaker as a part of more complex serving scenarios (i.e. ensembles, A/B testing, multi-armed bandit). This may help achieve the ultimate performance by selecting the best model for each user and aggregating predictions across multiple models.
To summarize, Amazon Personalize allows companies of different sizes and ML maturity to:
- Focus on personalized campaigns and experiences rather ML development
- Deliver fast iterations from an idea to production
- Automate end-to-end ML workflows at scale
- Achieve continuous improvements with new data
- Monitor and debug ML models in production
- Accelerate ML adoption across the company