
Future of VQA: How Multimodal AI Is Transforming Video Analysis
Introduction
Categorizing AI use cases into computer vision (CV) or natural language processing (NLP) tasks was common sense for a long time. However, recent advancements in AI research paved the way for multimodal AI models that simultaneously process various modalities' inputs, thus unlocking new possibilities in solving complex tasks.
The basic use case for multimodal LLMs is multimodal retrieval-augmented generation (mRAG), which allows understanding and generating insights on top of text and other structures like tables, images, and schemas. Such a powerful tool opens new opportunities and use cases for Gen AI: mRAG chatbot, visual-based search, LLM-based video analysis for summarization and captioning, video moderation, real-time question-answering, and other uses.
Imagine a security team overseeing a huge mall area through live video streams. With hundreds of people moving to various shops, keeping track of ongoing activities becomes a challenge. Putting in place a video question-answering (VQA) system based on visual-language models (VLMs) will help the security team during both real-time and historical analysis of the footage. This will allow the personnel to conduct searches using natural language queries such as "When and where was the last time the red bag was noticed?" to help find forgotten or stolen items in seconds, track people's behavior, and prevent unwanted situations.
This article examines the benefits of such an approach and describes SoftServe's implementation of a VQA solution for a use case in intelligent security.

Unlock business value with video analytics
Video data holds immense value for businesses, offering many insights into operations, customer behavior, security, and performance that will drive informed decision-making and operational efficiency.
However, video analytics is a complex task. There are many challenges related to historical data processing and extracting actionable insights. Manual monitoring is resource-intensive, error-prone, and often cannot offer real-time insights. Traditional computer vision models also struggle with scalability, especially when incorporating new functionalities, such as types of objects for monitoring and classification. Such improvements require machine learning (ML) models to be retrained and tested with more labeled data. That creates manual work to create these labeled datasets and expenses on computing units to run ML pipelines.
If there is a need to make the ML system robust in detection and classification, multiple models must be trained, deployed, and properly hosted. Using Generative AI (Gen AI) solutions will help overcome those challenges.
VQA powered by VLMs provides an effective solution to these challenges by enabling the following.
- NATURAL LANGUAGE QUESTION ANSWERING
(How is it Achieved?)
Due to multimodality, VLMs process both visual data and textual inputs at the same time. This makes them convenient for non-technical uses because the search query will be formulated as a natural language question. By posing fewer limitations on the query formulation, VLMs will unlock previously tricky insights. - REAL-TIME PROCESSING
(How is it Achieved?)
VLMs enable real-time video analysis by instantly interpreting visual data and generating answers to user questions. This capability allows businesses to quickly respond to critical events, such as finding security threats or monitoring equipment performance, significantly improving decision-making. In addition, SoftServe’s pipeline will enable a nearly immediate retrieval of insights from historical video recordings by accessing preprocessed information in an events log format. - EFFICIENT SCALING
(How is it Achieved?)
Developing and improving classical CV solutions for detection or tracking requires many resources, including an extensive set of manually labeled data and computational power. Using pre-trained VLMs enables faster development due to the richness of the initial train set and the versatility of extracted visual features.

VQA systems are highly beneficial in security surveillance, where operators may ask questions like "Are there any suspicious activities near the entrance?" and then receive immediate responses based on live video feeds.

In retail, managers may inquire about customer behavior with questions like "How many people visited the electronics section today?" to improve staffing and product placement.

Similarly, in manufacturing, supervisors may ask the model "Which machines are showing signs of malfunction?" to find and address issues quickly, reducing downtime and improving operational efficiency.
How video Q&A with AI works
Video processing with AI traditionally involves convolutional neural networks (CNN), which have proved the most effective in extracting both low- and high-level visual features. These models are effectively used in pipelines dealing with 2D (static frame) and 3D (a sequence of frames) inputs.
However, further steps like interpretation and analysis of model detections call for another type of architecture like recurrent neural networks (RNN) or transformer-based language models.
A VLM typically combines CNNs for efficient processing of visual input with transformer architectures for language understanding. The model first extracts features from individual video frames, identifying objects, actions, and spatial relationships. Then, these features are integrated with embeddings of the textual data, allowing the model to relate questions to the specific visual content and vice versa. Thanks to the attention mechanism, the model will focus on relevant parts of the visual input when generating answers, ensuring the response is accurate and appropriate to the query. This will allow efficient processing of more nuanced user queries, such as "What are the interactions between the workers at Gate C?" or general requests like "Provide me with a list of maintenance activities that were performed during the past hour."
Beyond VQA, VLMs may be applied in other ML tasks like image captioning or text-to-image generation. The versatility of natural language queries also allows VLMs' object detection and recognition abilities for information retrieval, anomaly detection, or even content recommendation.

Benefits of VQA: a real-world example
In this section, SoftServe presents its solution for intelligent surveillance — the CCTV camera assistant — a chatbot that enables users to interact with video data through simple queries, enhancing security monitoring and management.
The solution is based on VLMs and supports real-time and historical question answering on multiple video streams. The user selects one of three top VLMs for inference: GPT, Gemini, or Claude.
The first use-case for the solution was intelligent CCTV monitoring on oil and gas well sites. Multiple cameras were integrated with the LLM multimodal pipeline to provide immediate insights about current and past (up to 30 days) events.
The solution's design supports four primary tasks: scene description, object detection, activity classification and tracking, and sequence of events analysis.

SCENE DESCRIPTION
Environment understanding and detection of major scene changes, for example, weather conditions
🧑💻What is currently happening on Site5?
👷Selected timestamp: 00:02:05, MODEL: GPT
On Site5, there is a loader moving in the oil field fabrication yard which is used for open air storage of various equipment.

OBJECT DETECTION
Detection, identification, and tracking of vehicles and other machinery present within the location
🧑💻On what sites are there any vehicles present?
👷Selected timestamp: 00:02:05, MODEL: GPT
Vehicles are present at Site1, Site2, Site4, and Site5.
HUMAN ACTIVITY TRACKING
Detection and tracking of human activity that enables work process understanding
🧑💻What is currently hapenning on Site5?
👷Selected timestamp: 00:16:50, MODEL: GPT
On Site5, there are individuals engaged in work activities at an oil field fabrication yard with equipment and materials laid out in open air storage.

SEQUENCE ANALYSIS
Analysis of historical events, summarization of past activities, and change detection
🧑💻How many vehicles traversed this road?
👷Site6, selected time range: 00:00:00 - 00:08:20 MODEL: GPT
Throughout the described video segments, a total of five unique vehicles are visible traversing.
The pipeline of processing user input and visual information from the cameras' streams is shown below. 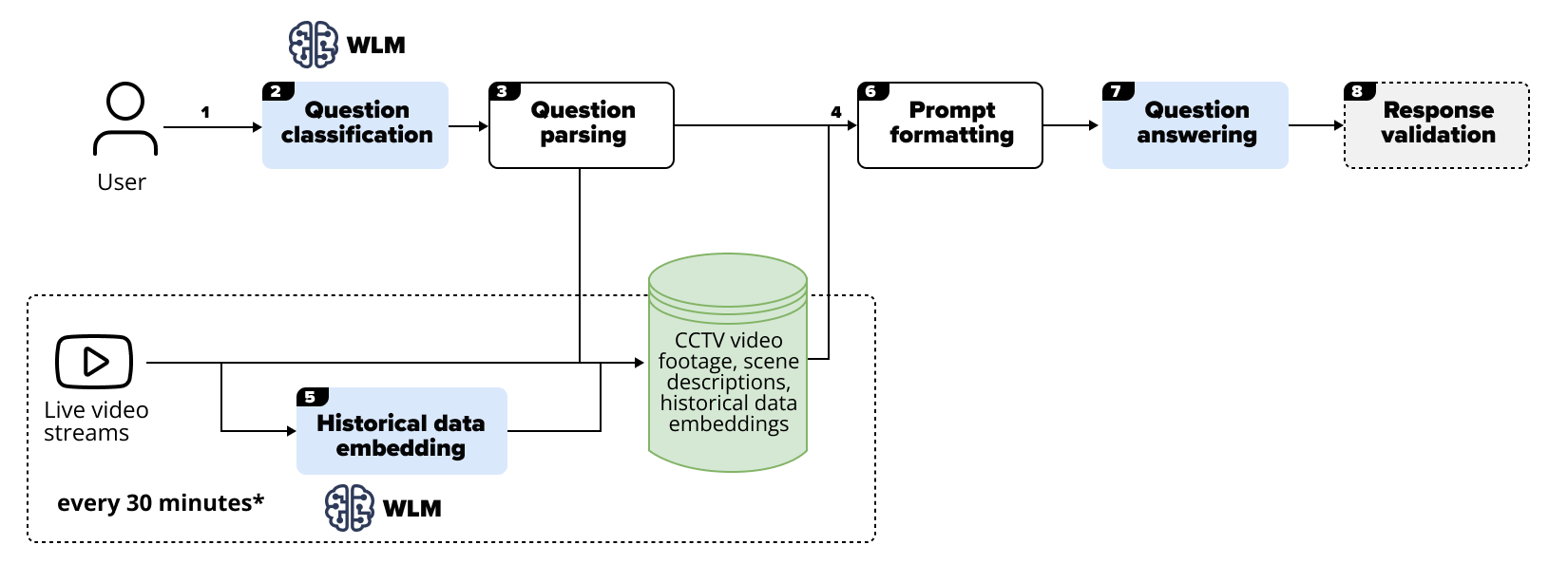
*time step can be varied depending on event-intensity of the footage to be processed
With a variety of scenarios that SoftServe’s solution analyzes, the processing pipeline involves multiple blocks.

User input
User input consists of natural language questions, selection between real-time and historical processing modes, and time range for the latter option.

Question classification
The question is classified as related to single or multiple video streams.

Question parsing
The question is parsed for critical information like names of locations or time marks.

Visual data processing
Most VLMs handle only 2D visual data, such as static frames. Thus, frames corresponding to selected timestamps from relevant locations are extracted.

Historical data embedding
To overcome the bottleneck posed by context length, the image captioning abilities of VLMs are used and long sequences of video frames are transformed into formatted textual descriptions. Such embeddings are created before user prompting to allow for a faster response time.

Prompt formatting
Processed user input is formatted and combined with instructions prompt to ensure high-quality results.

Question answering
The VLM formulates a natural language answer to user questions based on the context extracted from security footage.

Response validation
[Optional] In critical cases, it is recommended that the model response is validated through human oversight or cross-referencing with other data sources to ensure accuracy and reliability.
The illustrated pipeline is model-agnostic and applied with other VLMs, such as newer models from the GPT family or open-source models like large language and visual assistant (LLaVA). It is essential to remember that parameters like context length may significantly influence the quality of results. (With one input image, a few hundred tokens may be consumed.) Modern large language models (LLMs) also allow multiple visual inputs to be handled within one query.
The future is intelligent video analysis: take the first step
VQA with multimodal artificial intelligence (AI) unlocks new business capabilities for extracting real-time insights from vast video data through natural language interfaces. This advanced technology offers a substantial competitive advantage by streamlining processes and uncovering critical information faster.
It is time for you to discover how VQA will transform your business. Contact SoftServe for a consultation.
