

Managing big data is about much more than just storing, consolidating, or aggregating information. Modern big data solutions face a wide range of challenges, and the traditional “4 Vs” (Volume, Velocity, Variety, Veracity) don’t always capture the full picture.
In this article, we explore how Elasticsearch can help address these challenges and support your big data project’s goals. We’ll look at its capabilities, limitations, and practical considerations for using it as part of a data warehousing solution.
CHOOSING THE RIGHT TECHNOLOGY
When building big data solutions, there is no shortage of technologies and approaches. The key to success lies in selecting the architecture and tools that best fit your project requirements.
Elasticsearch is often thought of primarily as a search engine. However, its functionality extends far beyond search. By leveraging aggregates, it can also serve as a storage platform for reports and as a computing engine, especially when search-based filtering and aggregations need to be combined.
Elasticsearch offers several advantages for big data processing:
- Near real-time processing with around 5-second latency
- Low-latency aggregations on terabytes of data
- High throughput, handling tens or even hundreds of thousands of messages per second
- Support for hundreds of concurrent users
These capabilities make it a strong option for projects that require speed, scalability, and simultaneous access by multiple users.
WHEN ELASTICSEARCH WORKS AND WHEN IT DOESN’T
Despite its strengths, Elasticsearch is not a one-size-fits-all solution. In some scenarios, traditional data warehouses like Redshift may be more appropriate, particularly for near-real-time analytical workloads.
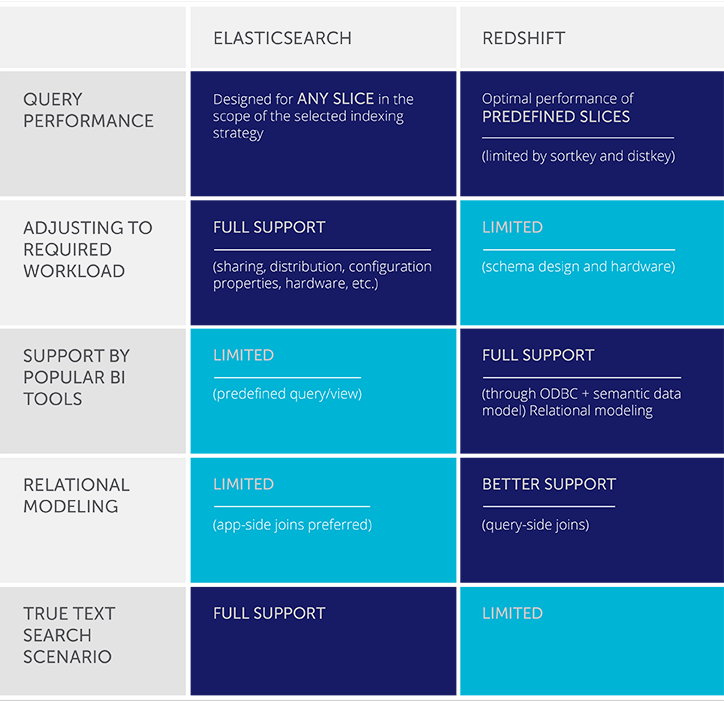
Before committing to any architecture, it’s important to initiate a prototyping phase. Technical risks are inherent in big data projects, and testing solutions on a smaller scale helps mitigate them before full implementation.
CONCLUSION
Traditional approaches often feel like the “path of least resistance” because they are familiar and carry lower risk. However, they may not always deliver the results your project truly needs. In many cases, alternative solutions like Elasticsearch can provide greater flexibility, speed, and scalability to help you achieve your big data goals.
With deep expertise in big data and analytics, SoftServe can guide you through any project, no matter its size or complexity, ensuring you select the right solution and achieve the best possible outcomes.
Start a conversation with us